
Preference Design
Introduction
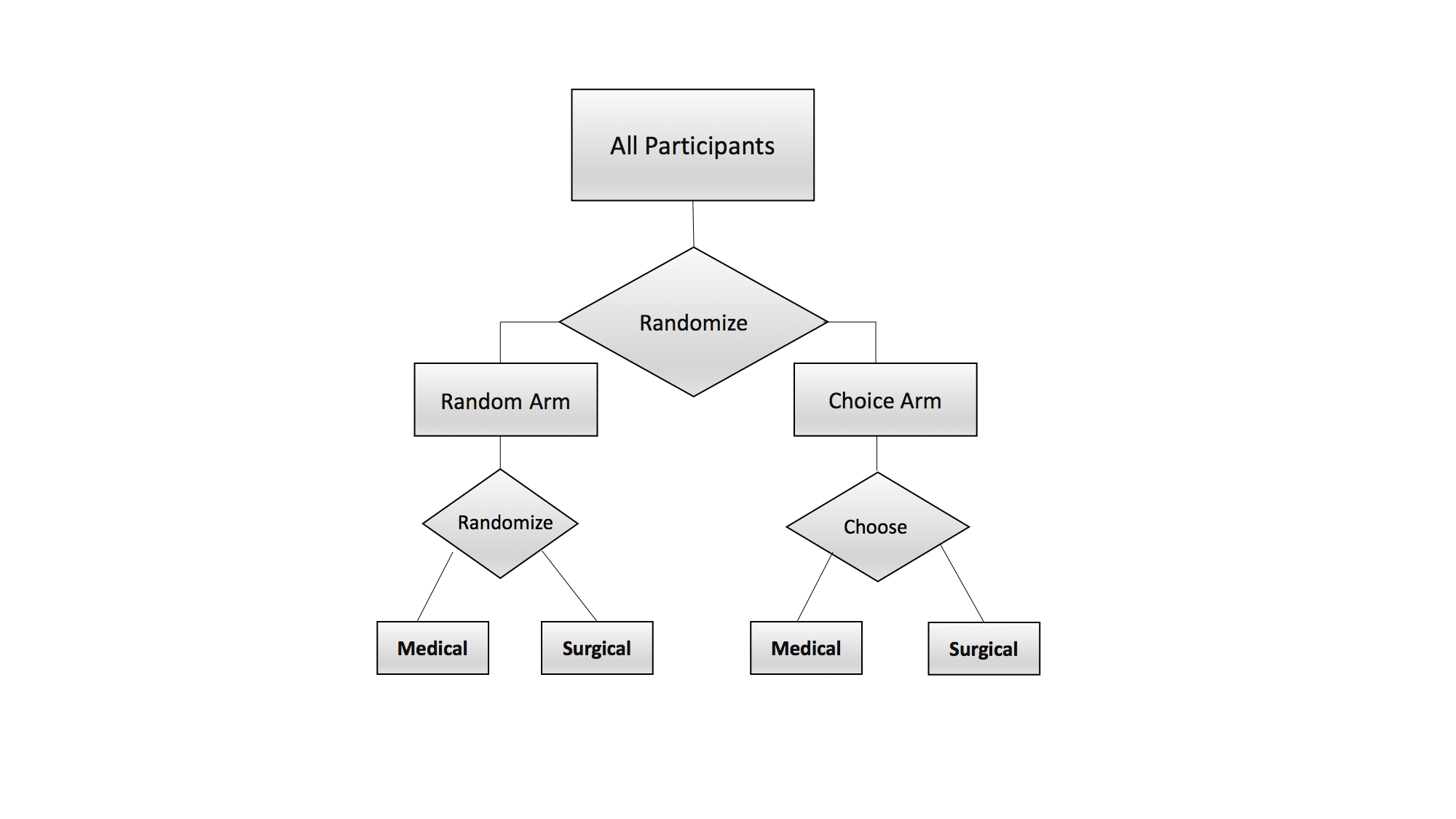
Suppose an investigator is interested in conducting a clinical trial to assess the effect of medical versus surgical treatment for low back pain. In the traditional clinical trial design, participants would be randomized to the medical or surgical arm with the express purpose of estimating treatment efficacy. However, this traditional design ignores the potential impact that an individual’s preference for a particular treatment may play on the overall effectiveness. This impact may especially be of concern in this example where participants are not blinded to the treatment arm: medical versus surgical. The two-stage clinical trial design [1], where patients are first randomized to a choice arm versus a random arm, allows for estimation of the standard treatment effect as well as a selection effect and a preference effect. The selection effect is the effect on outcomes from the self-selection of individuals into a particular treatment [1,3]. For example, this effect would capture differences in pain score between those preferring the medical intervention versus those preferring the surgical intervention. The preference effect measures the impact receiving the preferred treatment has on the outcome [1,3]. This effect would measure the difference in pain score between participants receiving their preferred treatments (e.g. prefer medical and receive medical or prefer surgical and receive surgical) and participants who do not receive their preferred treatment (e.g. prefer medical and receive surgical or prefer surgical and receive medical). From this two-stage design, the investigator is able to estimate how much the choice of a preferred treatment can impact the effectiveness of a given treatment.
Designing a Trial
In order to design a two-stage clinical trial, you will need to answer a few important questions:
What is the most important effect of interest? Is it the treatment effect, the preference effect or the selection effect?
What is the preference for one treatment over the other?
What difference (effect size) do we want to be able to detect between the two groups?
What is the variability in our groups?
Stratified Preference Designs
The above design assumes that the preference rate is constant across the entire population. However, this may not be the case. In some instances, there may be a variable that we would want to stratify the population based upon. In the medical versus surgical trial, this may be age. It may be that younger individuals would have a much higher preference for a surgical intervention compared to a medical intervention then older individuals. Based on clinical experience, we may hypothesize that the surgical preference rate in the younger population would be 80%, whereas the surgical preference rate in the older population would 65%. Under this scenario, we would want to implement a stratified design.
The stratified design is explored further in the Stratified Design Page.